Title Photo by Earvin Huang on Unsplash
I love comedy. It is fun and lighthearted, but surprisingly often the jokes highlight deeper insights. Let me give you an example.
Flight of the Conchords, a music-comedy duo made up of Jemaine Clement and Bret McKenzie, opened their HBO Live special in London by introducing themselves and recapping their career trajectory.
Bret starts, “We are one of the biggest bands in New Zealand now…”
Before the crowd can cheer, Jemaine interrupts, “…in terms of the number of members.”
The result is the first belly laugh of the night. It’s a great joke. Punchy. Self-deprecating. Ends with a surprise twist.
More than that, the joke also hits to a important but easily overlooked insight:
How you compare musicians drastically influences what you see.
People from all over the music industry have to decide how to compare musicians every day. How one chooses groups to draw comparisons against can radically change the insights and take aways.
Identifying a comparison group is never more tricky than when it comes to music genres. Where does one genre stop and another begin?
To try to visualize the problem, we pulled all the top artists from our database and measured the co-occurrences of genre tags. We put the results in a network graph, where each node is a genre and the links between nodes are co-occurrences. The more times that genres show up together, the stronger the nodes are attracted to each other. Try it out, with just a small sample of genres:
This visualization gives us a high-level perspective on how hard it is to cleanly separate genres. Some genre groupings do seem to naturally emerge (like how Swing and Bebop appear to be off-shoots of Jazz Blues), but more often genres overlap and blur strongly together. Pop and Hip Hop are highly connected to many nodes — so no natural distinctions emerge between them.
Even though it is tricky to draw boundaries around genre, it can be extremely helpful because it contextualizes an artist’s performance in relationship to their competitive peers. In response to this challenge, we decided to build a tool that helps people make meaningful comparisons between artists. To build the best tools though, we have to know why people want to compare artists at all.
Why Compare Artists?
Comparing artists is both one of the most common and the most useful techniques to get perspective on artist performance. Usually when people make comparisons between artists, it is because they want to know more about a specific artist (we’ll call that the “target artist”). At a glance, we can tell how the target artist is performing by comparing them:
- across the music industry in general.
- against their direct competitors.
In both these scenarios, we need to see artists that are “similar” to our target artist. But if you really dig into this, you’ll realize that we often need to have different reference groups for each of those insights.
In both analyses, we may say that we want to compare an artist to similar artists… but each relies on a different definition of “similar.”
Two ways to identify “similar” artists:
We built the “neighboring artist” feature on Chartmetric to help you quickly assess artist performance. You might be familiar with it already. Going forward, this feature will have two options for grouping artists, and it is worth looking into how the two methods offer different insights.

Method 1: Universal Sorting on Similar Performance
The original option with our “Neighboring Artist” feature allows users to specify a single metric, and we return a list of artists that perform similarly. Often this is incredibly helpful for determining how an artist is doing across the music industry in general.
Let’s look at a quick example. Let’s say that I want to understand the Spotify performance of Kendrick Lamar.
I can see that Kendrick Lamar has 23.76 Million monthly listeners on Spotify… but I may wonder how successful that actually is.
By comparing my target artist to artists with a similar metric (i.e., monthly listeners on Spotify), I can get an idea:
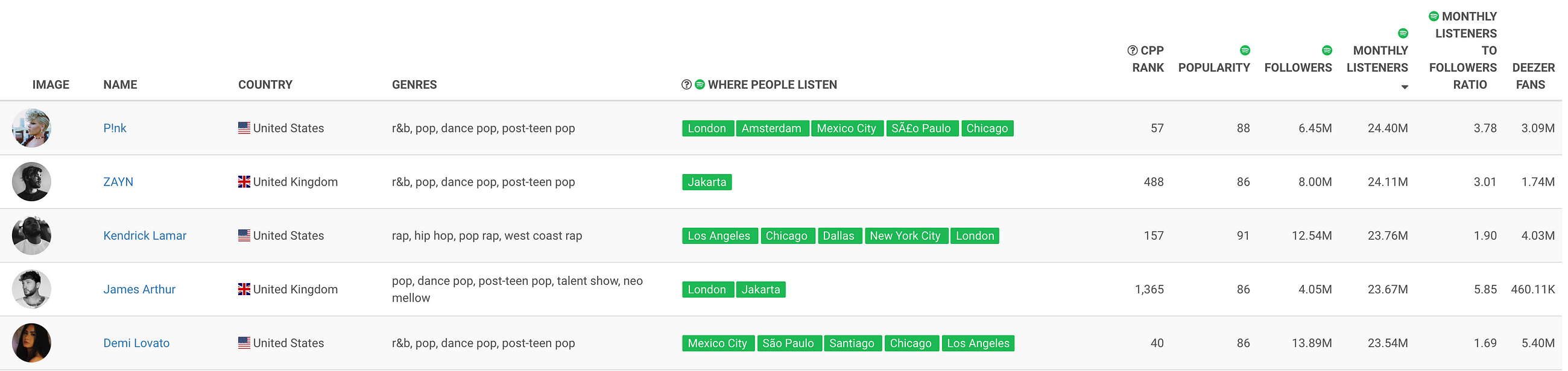
Kendrick Lamar is right between P!nk, ZAYN, James Arthur, and Demi Lovato. Each of these artists is a power performer, so now I feel like I’ve got a better idea of what “23 million” monthly listeners means. It seems to be a pretty elite tier of performance.
What’s more, I can compare these artists across other metrics, too. Kendrick Lamar has a similar number of monthly listeners as James Arthur and ZAYN, but he is doing much better on our measure for Cross-Platform Performance (CPP). He’s trailing P!nk and Demi Lovato on CPP, but he’s leading this pack on Spotify Popularity. I can easily see the nuance of how these artists are situated.
Comparing artists by the similarity of their performances works especially well for popular artists because each neighboring artist is often well known.
Pretty cool.
Method 2: Cluster Artists By Genre of a Similar Type
However, that first method is not always the right comparison to make because it compares performance across genres without accounting for contextual clues. Let’s take a look at another example, where comparing by performance is less helpful. Let’s say I want to look at how John Prine is performing on YouTube channel views:
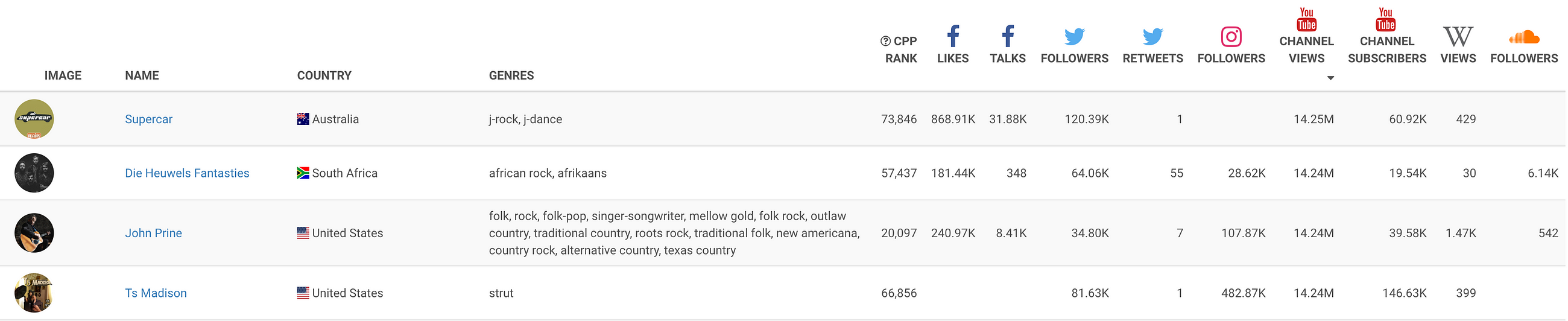
We have a wide range of artists across different genres and regions, and it is not immediately clear how to make sense of this information. Personally, I’m not familiar with any of the artists around John Prine. We have an Australian j-rock/j-dance band, a South African band doing African rock and Afrikaans, and an American artist doing “strut.”
I thought “strut” was what I did through my grocery store vegetable section, but apparently it’s also a music genre.
Unlike the Kendrick Lamar example above, I don’t gain much insight from comparing John Prine to artists with similar performance. Because I am not familiar with the other artists, they are not a great reference point. I suppose this could be due to my own music ignorance (I’m a data-nerd after all — a certain degree of social ignorance isn’t too surprising). But no one can be expected to know all artists. Even the most savvy music aficionado will eventually run into comparison artists with which they are unfamiliar.
Without knowing the comparison artists, I cannot get much perspective on my target artist. Look at the other performance metrics, like the Cross-Platform Performance rank. Is John Prine ranked higher because he is a great artist? Or is his higher CPP rank due to his staus as a more mainstream artist, while the other artists are in more obscure genres? The answer to these questions is not immediately clear.
How could we improve this comparison?
Even if I don’t know every artists’ name and performance, it can be helpful to see comparison-artists that are in the same genre as my target-artist. If I could see how other ‘folk, rock, singer-songwriter’ artists are performing on YouTube, I could more accurately make sense of how John Prine is doing. What I want is data on artists that are of a similar type to the target artist.
If we were to compare artists within a single type, then we would want see results like these:
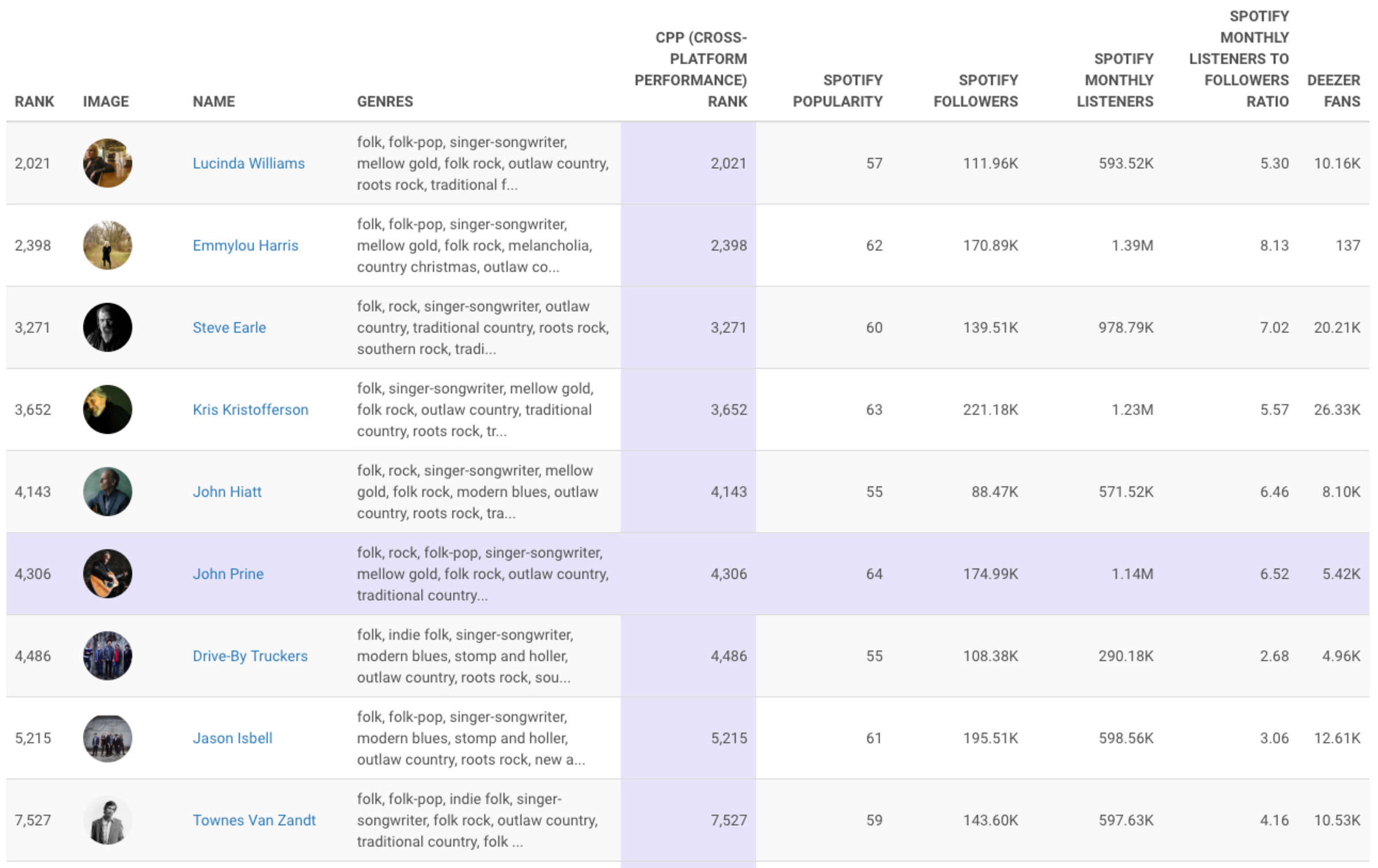
Now we can see that John Prine is one of the top in his genre by Spotify popularity and monthly listeners but he’s trailing behind on CPP, Spotify followers, and Deezer. Overall, John Prine is doing alright among his genre-peers, but he’s far from leading the pack of singer-songwriters.
Intra-genre comparison gives me a completely different perspective compared to that of Method One described above. This comparison can help me evaluate how competitive my target artist is within a particular listener base, or it may help me find similar artists to try to work with on tours or collaborations. Emmylou Harris would be a good artist for me to keep an eye on, as both Harris and Prine seem to have similar performance and audiences.

What are the Benefits of Machine Learning?
Couldn’t we just filter artists based on genre? Doesn’t that basically do the same thing? Fair question.
Cluster analysis does something slightly different than filtering and has two major benefits. First, it finds natural associations instead of exact matches. Second, it minimizes personal bias.
AI Benefit #1: Natural Associations Emerge from Multi-Dimensional Space
If you filter, you have to create categories manually and filter based on an exact match. So suppose we create some categories like:
Pop, Rock, Hip-Hop, Indie, Country, Metal, EDM, and Classical
Using that list we could filter, say, Pop artists to be grouped together. Seems like it makes sense. If you give me Katy Perry, I can give you back Taylor Swift and Ed Sheeran. Cool.
But you don’t have to go far to run into problems.
What do we do with genres like K-Pop? Or Heavy Metal? You could lump these examples with a “parent” genre (e.g., Pop and Metal respectively).
But going deeper, you run into trickier problems. Where do we put Indie Electro-Pop? Is it Indie or is it Pop? The answer is not immediately clear.
While identifying a single parent genre for Indie Electro-Pop isn’t immediately obvious, it is fairly obvious that Indie Electro-Pop is “closer” to Indie, Electronica, and Pop music than it is to Heavy Metal or Grunge.
The promise of machine learning is that we can run an algorithm that “learns” how similar or dissimilar genres are based on how frequently they co-occur in artists profiles. Artists that are identified as playing Pop, Indie, and Indie Electro-Pop will increase the association between those genres. If you’re not up on machine learning concepts and terminology, then all you need to know is that we’re just observing how similar genres are to each other out there “in the wild.” If you’re up-to-date on ML, you’ll realize that we’re talking about plotting genres in a multi-dimensional space and measuring how far apart they are.
Because “plotting genres in multi-dimensional space” can be hard to conceptualize, here is a simple example.
An Example of AI Clustering: Kane Brown
Let me show you an example of how this looks in action, inspired by the genre tags associated with artist Kane Brown. I see that Kane Brown is identified as playing “Contemporary Country” and “Country Road”.
If we wanted to compare Kane Brown to “similar” artists, who would we pick? Kane Brown has blurred genres beyond just “country” music, so filtering on country isn’t the best bet. We’ve talked elsewhere about how Becky G introduced him to the Latin music world through a collaboration–so how would you categorize this track?
Categorizing that one song is difficult, let alone Kane Brown’s entire repertoire. Does this mean Country Road is Latin infused? Or is his collaboration with Marshmello a better example of Country Road? Instead of relying on my own knowledge (which is limited) to try to collapse Country Road into a parent genre, we can use machine learning to track how often that genre tag co-occurs with other genre tags.
For simplicity, I’ll only take a very small sample of artists (12) and put their genre tags together into a list. Each row represents one of my 12 artists’ genre tags:

Just with this list, we can start to get an idea of how Country Road is situated around other genres. We can already infer that:
Country RoadandCountry Dawnalmost always show up together- Artists that play
Country Roadalso often playContemporary Country Contemporary Countryoverlaps withModern CountryandPopjust as much as it overlaps withCountry RoadPopandChristmas Popnever overlap withCountry Dawn
We can see those patterns with our own eyes, since this list is only 12 entries long. But it would be better to get a computer to do it instead, because then we could scale the process up to millions of entries. If only some very savvy people had spent a lot of time pioneering a range of techniques to turn observations about similarity into quantifiable results… Oh wait! They have! Hey thanks, Data Scientists! (Although, its probably more accurate to say, “Thanks Statisticians.”)
We can use cosine similarity with this list of artist genres to calculate a single numerical value that captures the degree to which each term is associated with each other. You can read a lot about cosine similarity elsewhere. It’s a fascinating and handy tool, but I won’t clutter this article by going into it here. Let’s look at the top results, and I’ll help explain how to interpret them:
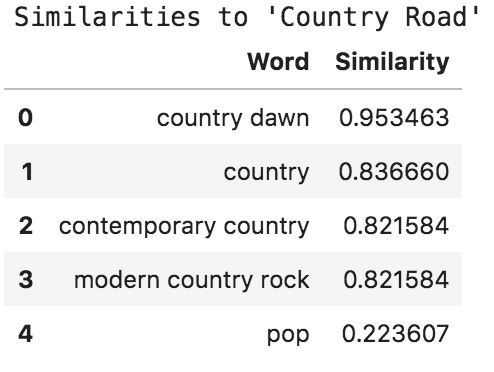
You can connect these numbers directly to our insights above:
- Because
County RoadandCounty Dawnalmost always show up together,Country Dawngets the highest similarity value (0.95) Country,Contemporary Country, andModern Country Rockall commonly overlap withCountry Road, so they have relatively high values (0.82–0.83). But because those tags also show up withoutCountry Roadsometimes, their association values are lowered.Popnever shows up withCountry Roadso its score for “similarity” is very small (0.22).
Well look at that, these numbers match up with the exact same insights that we created by manually looking at the list. That’s handy! If we were to expand our scope to include even more genre tags, we would really start to get a profile of Country Road and understand where it fits with the overall music.
This is just a small sample to illustrate how measuring similarity works. We can easily apply the same process to all 1.5 million artists in our database while looking at 1657 genres.
AI Benefit #2: Removal of Personal Bias
One of the biggest perks about machine learning is that personal bias is greatly minimized. In the above example, I didn’t decide whether Country Road is legitimate Country. I don’t get to act as a gatekeeper about what “is” and what “is not” inside a parent genre.
Instead, the landscape of musicians decides organically. Proximity is measured as a result of artists’ identification with similar genre-tags. If a lot of people who play “Pop” also play “Indie Electro-Pop,” then we draw a stronger association between Indie Electro-Pop and Pop.
Now you’ve seen some benefits to unsupervised machine learning for clustering, but how it is actually done? Read on, dear reader. Read on.
Nuts and Bolts to Genre Clustering
So when we began our mission was: “Group genres by co-occurrences. The more genres show up together, the more coherent a group they make.”
Sounds easy!
And… it is easy… if you know some Natural Language Processing (NLP). Be aware though, that the NLP decisions you make will impact how the genres are grouped. How? I’m glad you asked.
Of course, you know that computers don’t actually read text, they just work with numbers. In order to compare two instances of text (for us that is two artists’ lists of genre tags), we have to translate the text into a format that a computer can understand. Computers have no concept of what “pop,” “jazz,” or “strut” are. That also means:
A computer does not inherently know that there is some association between “pop” and “indie pop.” We have to tell it how to parse these phrases.
There are a lot of machine learning buzzwords related to the process of parsing text into computer readable formats, and maybe you’ve heard of some of them: bag of words, tokenization, one-hot encoding, count vectorizing, dictionary vectorizing, and TF-IDF, to name a few.
Each is important (and in fact we used each at different points), but I’m going to give you a high-level overview of how they affect our process differently.
Take two hypothetical lists of artist tags. We’ll reuse some of the example tags we saw above.Artist 1 - {'contemporary country', 'country road'}
Artist 2 - {'country', 'pop'}
The simplest way to parse these genres is to break out every single word by itself. Then, we keep a master list of all the words and count up the number of times each word from the master list shows up in each entry.
The consequence of this method is that it obliterates word-order and context. Here, we treat all words exactly the same, essentially just throwing them into a single bucket or… a bag. (Hint: this is the “bag of words” method!)
Our lists have a combined total of 4 unique words ( contemporary, country, road, and pop). So applying the bag of words method, we get this result:Artist 1 - {'contemporary': 1, 'country': 2, 'road': 1, 'pop': 0}
Artist 2 - {'contemporary': 0, 'country': 1, 'road': 0, 'pop': 1}
From this, you can easily see how the artists diverge in almost every case, but they do overlap on the word country. Using each artists’ degree of overlap, we can start to measure how similar or dissimilar each artist is from one another. This method is a staple of NLP because it is remarkably effective and easy to implement.
Still, there are situations where this method would fall short. What about the following list?Artist 1 - ['pop', 'christmas pop']
Artist 2 - ['comedy', 'humor', 'pop parody', 'christmas parody']
These artists would show up as having some overlap because they have counts for both pop and christmas even though the contexts are very different. The second artist here is doing a completely different style of performance. In fact, they might be a stand-up comic! You can see that the additional context we get from identifying that parody follows pop is really important. Now you see why word-order, the very thing we threw out in bag-of-words, is important.
There are two methods available to help us capture word-order information:
- N-grams : We take all the combinations of words in our bag of words and count the combinations. We would start with
pop, christmas, comedy, humor, parodybut also addpop christmas, christmas pop, comedy humor, humor pop, pop parody, parody christmas, christmas parody. This will capture word order without a problem. Artist 1 will have no instance of'pop parody'or'christmas parody', which will help us draw dissimilarity between these artists. We’ll still see them overlap onpopandchristmas, so this solution still isn’t perfect. This also has the potential to spiral out on memory usage because the number of combinations increases exponentially as your number of words increases. - Dictionary Vectorizing : Alternatively, we can require that every genre tag be an unique entity and only count perfect matches. By doing this, we turn the list above into
Artist 1 — {‘pop’:1, ‘christmas pop’:1}andArtist 2 — {‘comedy’: 1, ‘humor’: 1, ‘pop parody’:1, ‘christmas parody’:1}. This solves the problem that we ran into with n-grams because these artists now do not overlap at all! That seems great right? We have all of our genres distinct and we can tell when someone is a comedian versus a serious musician! However, this is a double-edged sword. Now our algorithm can’t tell that an artist who doesfolk rockis similar to someone who doesrock. Because every genre is unique and has to match perfectly, our computer seesfolk rockas no more similar torockthan it is toclassical performanceorscreamo metal. Well, that’s not ideal. Similarly,hip hopandhip-hopcount as distinct genres, too. That’s bad — alternative spellings lead to all sorts of problems.
Even with all of these methods available to us, there is clearly no silver bullet to all of our problems. Each decision clarifies in some instances and hurts in others. Still, there are some techniques that are generally a good idea. For example, replacing all instances of hip hop and hiphop with a uniform spelling of hip-hop will help us get more consistent results.
NLP would be a lot easier if there were a consistent playbook that guaranteed good results, but alas you have to experiment with what works best for your use case. I’ll cut to the chase and show you what seemed to work best for us.
Steps to Create Chartmetric Genre Clusters for Artists
Step 1 - Genre Cluster Analysis Using Dictionary Vectorizing: This catches the distinctions between categories like pop , pop parody, and K-pop. It helps us make fine-grained distinctions between groups. For the artists that this stage worked for, the clusters work pretty well. (TF-IDF helped here too, but let’s not open that can of worms in this article.) Using this method, we get finalized clusters for about 80% of artists.
Step 2 - Identify Ineffective Clusters: The first step did not work for about 20% of artists, but why? Looking at the data, we had two problematic groups. One cluster was radically larger than every other cluster. We looked into it, and it turned out this was a “catch all” cluster. Every artist in that group was similar insofar as they were uncommonly unique. The second cluster comprised every artist that was missing genre tags–the “null” cluster.
Step 3 - Address the “Catch-All” Cluster with a New Bag of Words Analysis: Artists in this cluster had super specific genre tags. For example, it is hard to group artists with tags like Finnish emo electro-indie death metal when you are matching genres exactly (which we were doing in the dictionary vectorizer in Step 1). In the first step, an artist in this category would be tagged like this: {Finnish emo electro-indie death metal: 1} Instead, we run a new cluster analysis using the bag of words method. The above artist now has {Finnish: 1, emo: 1, electro: 1, indie: 1, death: 1, metal: 1} . With that kind of profile, we can start to tell that this artist overlaps with other emo , metal, and indie artists. For the artists in the “catch-all” cluster only, we update their initial cluster id with their new cluster id.
Step 4 - Address “Null” Cluster with New Data Sources: A lot of artists did not have genre tags directly associated with their artist profile. That makes it pretty impossible to match them! Fortunately, we also have genre tags associated with specific songs/tracks. We went to each artist’s catalogue, picked their top songs , gathered the genre tags associated with those tracks, and lifted those genre tags to be associated with the artist. This method is less effective than the initial cluster, so again we only update the cluster identifications for artists that were in the original “null” group with the results from this analysis. (We still have a number of artists that are missing genre data and are actively working to incorporate different data sources to fill in our blind spots.)
That’s it! All the hard work is done.
We just have to bring all the correct cluster identifications together into one spot so we can quickly refer to and assess each cluster.
Our machine learning model determined the groups, so we have to do a quick assessment of each cluster to get an idea of what brought them together. We went cluster-by-cluster and counted up all the genre tags within each cluster. Now whenever we select a cluster, we also return the top 5 most common genre tags in that cluster. That gives us an idea of the types of artists that were brought together in that cluster.
Here’s an example of an artist, their cluster, and some of their new neighbors:
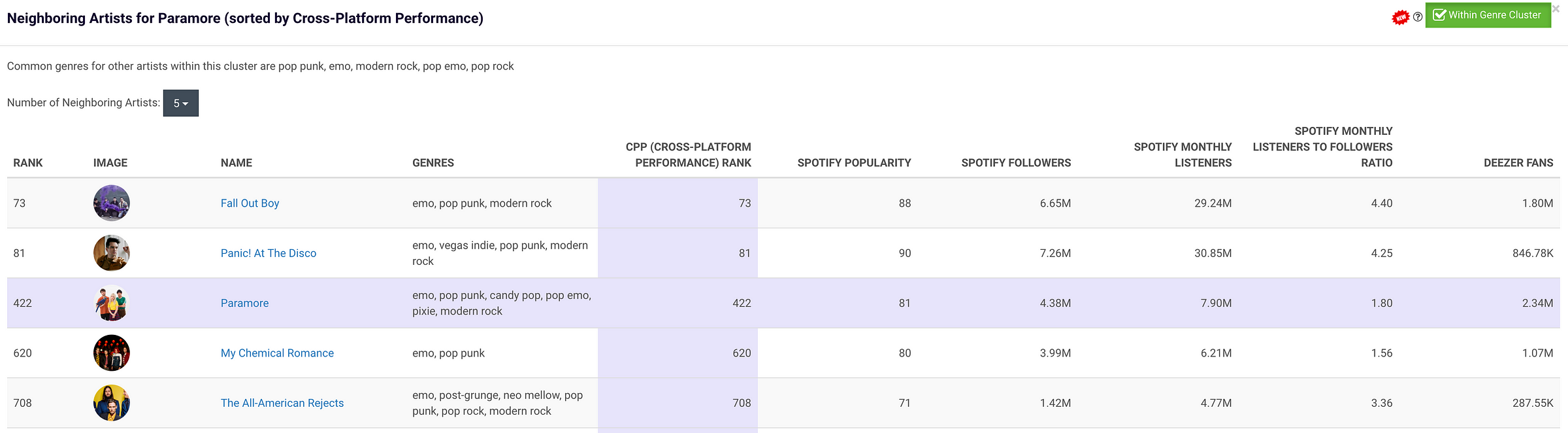
You can check this new feature out on the Chartmetric website right now. Simply click on any metric for any artist to bring up a universal comparison on that stat. Then click the green-toggle labeled “Within Genre Cluster” in the upper right corner to compare within your artist’s genre cluster.
Shout out to Komala Prabhu Tirupachur and Greg Yannett for their critical roles in helping this feature go live.